Diving into Docker
2021-02-10
One of the technologies that I’ve been meaning to get the hang of for a while is containers. I’ve been coming across more and more teams that are using containers in their day to day workflows and deployment pipelines and thought it was finally time for me to take the plunge.
So why have I put off learning more about containers and Docker for so long? Well, the simple reason is that I was able to manage without them. I’ve been able to get by just fine using virtual environments and multiple tmux panes for development and keeping myself well away from anything deployment related. Also, with smaller projects different backing services can be singular and fairly independent but as the scale of projects grows, you can find yourself working with multiple backing services and dependencies, sometimes even the same services with different versions.
I found myself in a similar situation recently. More and more of my time was being spent in making sure that the dependencies for the different projects I was working on are in order. As the different components of these projects have turned into parts of a larger architecture, there isn’t a strict isolation of the underlying backing services anymore either. This meant that there was a jumble of different libraries with their own versions and dependency conflicts between them, making their management during development unwieldy. To be specific - with the addition of new components to the software, the differences between the dependencies for these components in our development, staging and production environments started to become quite stark. These differences should ideally be as few as possible. So with all the incentives now there I took some time out to understand containers better.
Just to note - this post is about linux containers. Docker works with linux containers and when we run Docker on an operating system like Mac or Windows, Docker starts up a lightweight linux virtual machine on the host machine using Hyperkit (on Macs) and then runs containers within these virtual machines.
What is a container?
From the docs,
A container is a normal operating system process except that this process is isolated in that it has its own file system, its own networking, and its own isolated process tree separate from the host.
There is no such thing in linux called containers. A container is actually just a filesystem (container image) that is used with a set of linux features (cgroups, namespaces, seccomp, selinux, etc.) that provide a thin layer of isolation between processes running in that container and all the other processes on the host machine.
We usually run a container per application service we want to have and although running multiple services is possible, it is not recommended and since containers are so lightweight, not really required.
What problems do containers solve?
Using containers we can package together all of our application code or binaries, the dependencies required to run these (including the runtime environment) and the necessary configuration parameters. Using containers, we can have the exact same setup on all the machines that the container is run on. So no more manual management of environments, no dependency resolution, no setup scripts whatsoever. Just download the container image and have the application and everything it requires up and running. That solves a lot of pain points not just in the development of the application, but also in its deployment because we’re working with a completely reproducible and consistent environment.
The isolation of processes between containers also means that two containers running on the same machine can have conflicting dependencies and that won’t be an issue as the dependencies used by the application of one container have nothing to do with the dependencies of the other application.
But, as mentioned, containers are just a filesystem that is used with some linux features. We still need applications that run on the host machine, abstracting away the use of these features and coordinate setting up and managing containers for us. This is done by engines like Docker and Podman.
Containers vs Virtual Machines
With all the talk of independent filesystems and process isolation, the first question that pops into mind is how are containers different from virtual machines? Virtual machines use hypervisors to share the underlying hardware of the host machine with all the instances of virtual machines that are being run on it. This means that every virtual machine is running not just its own operating system but also its own kernel. Containers on the other hand are just logically separated groups of processes started and managed by the operating system running on the host machine.
How are container images built and used?
Images are specified with a Dockerfile that carries instructions on how to build these images. We start out with a base or parent image and add instructions to make changes to it. Each instruction (FROM, RUN, COPY, etc.) inside the Dockerfile corresponds to a layer of the final image. Container images make use of Union or Overlay filesystems that are layers of filesystems where the common components reside within the initial layers and are read-only. So the Dockerfile can be seen as a series of diffs that are applied to the parent image which is read-only. When a container is started from an image built from a Dockerfile, a final read-write capable layer called the container layer is added on top of all the other layers and any write operations happen only on this layer. If some parts of the read-only layer need to be modified, a copy of the specific part is made to the container layer and is then modified (copy-on-write). When we stop and remove a container, the container layer is lost but the underlying image layers remain unchanged. You can dive deeper into how this works in this section from the official docs. Union file systems also help in reducing the size of different containers because the underlying layers can be shared and reused by different container images.
It would be good to note that container images are immutable. Once images are built, they can’t be altered but they can be added on to.
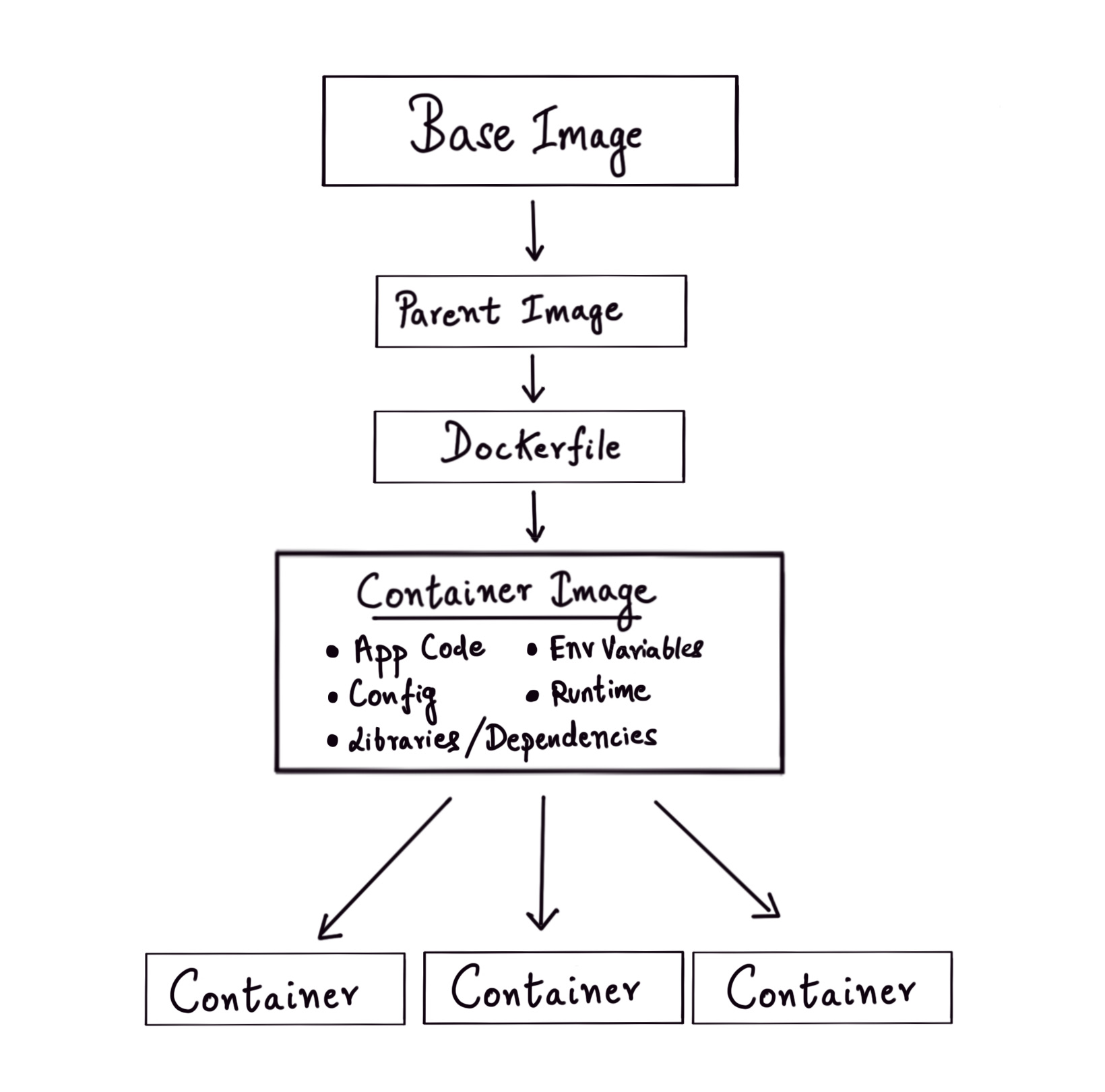
A question that I had when I started learning about containers is about the parent image used. If containers are just lightweight processes inside the host operating system that have been logically isolated then what does it mean when we use an image that is based on a different operating system? For example, If I’m running Manjaro on my machine then what happens when I run a container image that has Ubuntu or CentOS as its parent image?
The answer to this is actually quite simple. FreeBSD and its derivative MacOS don’t actually consider the kernel and the operating system to be separate and these are treated as a single unit. In contrast, there is a distinction between the linux kernel and the operating system running on a linux kernel. The same kernel can be used by different operating systems. The only difference between linux distributions is the userland software.
In the linux kernel, memory gets divided into two areas - the user space and the kernel space. Simply put, the kernel memory space is where the code for the kernel resides and is executed whereas everything else is the user space (all the processes started by the operating system and within it). The kernel has access to and coordinates all the available memory including user space memory but user processes can only access a small part of the kernel via system calls. These system calls are exposed to the user space by low-level libraries like libc or glibc which are distributed within operating systems and so can be included in a container image. So when we start a container with a parent image different than that of the host operating system, the filesystem root for that container gets user land software from the container image (including libc/glibc) and thus is given access to the host machine kernel. Basically only the libraries and dependencies are different for different container images and nothing else changes!
How do containers actually work?
Containers mainly rely on 3 things - cgroups, namespaces and overlay file systems to provide the ‘container’ functionality. We’ve already gone over how file system layers work in Docker.
This is what the docs say about namespaces:
Namespaces provide the first and most straightforward form of isolation: processes running within a container cannot see, and even less affect, processes running in another container, or in the host system.
And cgroups:
Control Groups are another key component of Linux Containers. They implement resource accounting and limiting. They provide many useful metrics, but they also help ensure that each container gets its fair share of memory, CPU, disk I/O; and, more importantly, that a single container cannot bring the system down by exhausting one of those resources.
The functionality of Cgroups is simple enough to understand. Let’s see how namespaces work under the hood. If you have a linux machine with Docker running, you can start a lightweight alpine linux container and log into the shell using the following command.
$ sudo docker container run -it alpine sh
If you're on a mac, you'll first have to get access to the linux virtual machine that is running on your mac. You can do this in this way:
$ docker run -it --rm --privileged --pid=host justincormack/nsenter1
For more information, see this gist.
Inside the linux container shell, run ps aux to see the list of all processes that are running inside the namespace of this container (there won’t be many).
$ ps aux
PID USER TIME COMMAND
1 root 0:00 sh
7 root 0:00 ps aux
Now, run sleep 200 and halt the process using Ctrl-Z. Again, on the shell run another sleep process sleep 300 and halt it. Run ps aux inside the container shell again to see the two halted sleep processes that were started by you.
$ ps aux
PID USER TIME COMMAND
1 root 0:00 sh
8 root 0:00 sleep 300
9 root 0:00 sleep 200
10 root 0:00 ps aux
Open a separate terminal on your host machine and run ps aux to see the list of processes. You will see the two sleep process inside this list. These sleep processes will have PIDs that are different than the PIDs of the sleep processes that you saw inside the container shell.
/ # ps aux
PID USER TIME COMMAND
1 root 0:05 /sbin/init
2 root 0:00 [kthreadd]
3 root 0:00 [rcu_gp]
4 root 0:00 [rcu_par_gp]
...
30579 root 0:00 sh
30614 root 0:00 sleep 200
30615 root 0:00 sleep 300
30833 root 0:00 [kworker/0:1-vir]
...
In fact, these are the very same processes that are running inside the ‘container’ we started. Processes inside the container are isolated within the namespace of that container but are ultimately run as processes inside the host operating system.
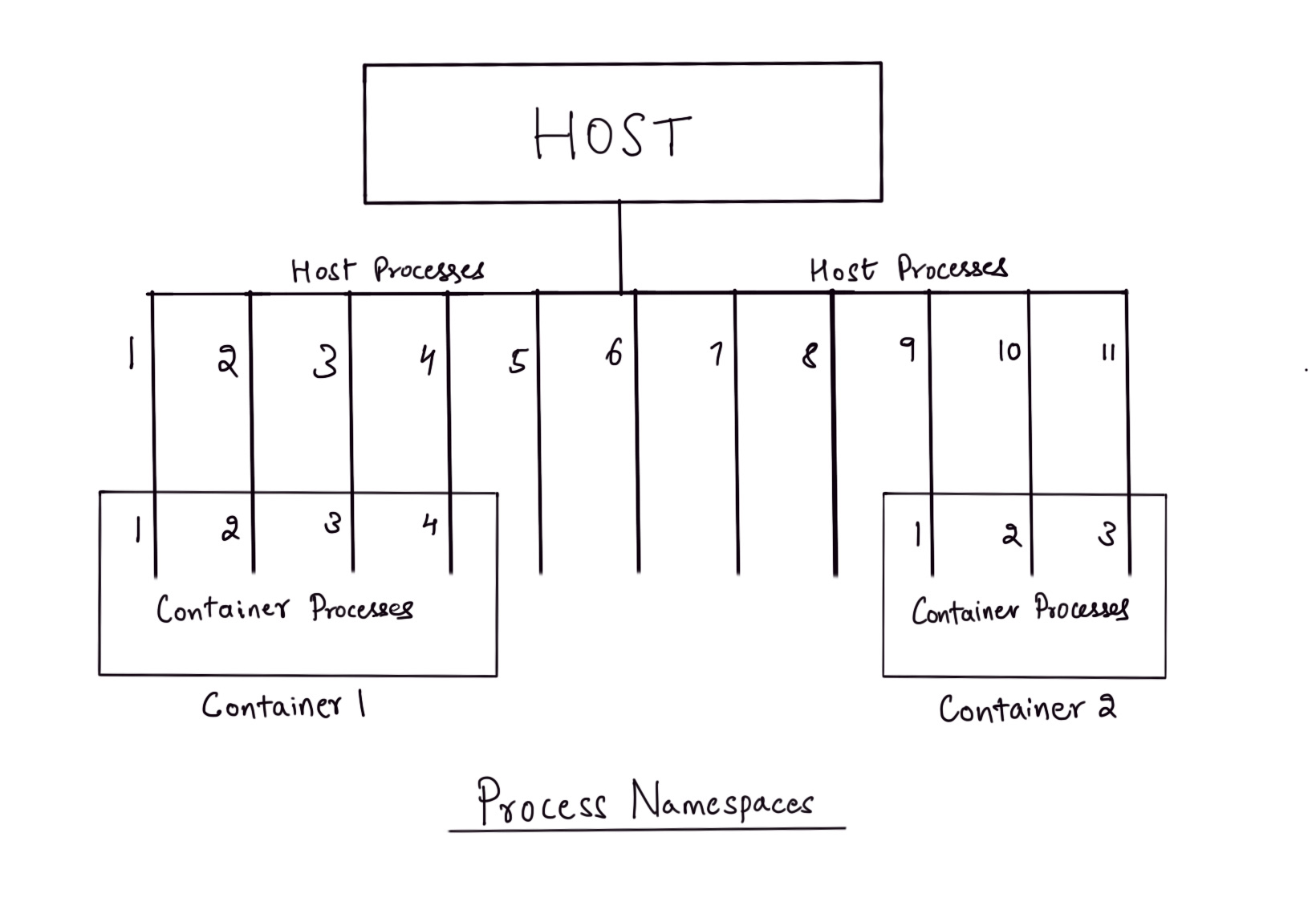
Since containers are just processes, applications running within containers can be started and stopped really fast and this functionality pushed to its extreme is what serverless services like AWS Lambda offer. A container is started per request that comes through and only lives for the duration of that request! Containers can also offer an easy way to shift to multi-tenant applications where you require running the same application but for different clients. Without making any changes to the application, you could just start a different instance of the application per client and run an internal service that can aggregate the data from these applications if required.
Containers could likely solve a lot of pain points for you but it would be worthwhile to understand where and how they can fit in your overall workflow. Container registeries, using docker-compose for container orchestration, configuration and secrets management while building and deploying images, simplifying CI/CD pipelines using containers and microservices are just some of the things you can explore after this post.
References:
- https://stackoverflow.com/questions/16047306/how-is-docker-different-from-a-virtual-machine?rq=1
- https://stackoverflow.com/questions/20274162/why-do-you-need-a-base-image-with-docker/62384611#62384611
- https://serverfault.com/questions/755607/why-do-we-use-a-os-base-image-with-docker-if-containers-have-no-guest-os
- https://unix.stackexchange.com/questions/87625/what-is-difference-between-user-space-and-kernel-space
- https://unix.stackexchange.com/questions/57232/difference-between-system-calls-and-library-functions
- https://forums.docker.com/t/libc-incompatibilities-when-will-they-emerge/9895/4
- Julia Evans’ excellent and informative zines!